

Introduction and Motivation
It is becoming increasingly common for organizations to collect very large amounts of data over time, and to need to detect unusual or anomalous time series. For example, Yahoo has banks of mail servers that are monitored over time. Many measurements on servers/IoT device performances are collected every hour for each of thousands of servers in order to identify servers/devices that are behaving unusually.
Python library tsfeature helps to compute a vector of features on each time series, measuring different characteristic-features of the series. The features may include lag correlation, the strength of seasonality, spectral entropy, etc.
In this blog, we discuss about different feature extraction techniques from a time-series and demonstrate with two different time-series.
Popular Feature Extraction Metrics
One of the most commonly used mechanisms of Feature Extraction mechanisms in Data Science – Principal Component Analysis (PCA) is also used in the context of time-series. After applying Principal Component Analysis(Decomposition) on the features, various bivariate outlier detection methods can be applied to the first two principal components. This enables the most unusual series, based on their feature vectors, to be identified. The bivariate outlier detection methods used are based on the highest density regions.
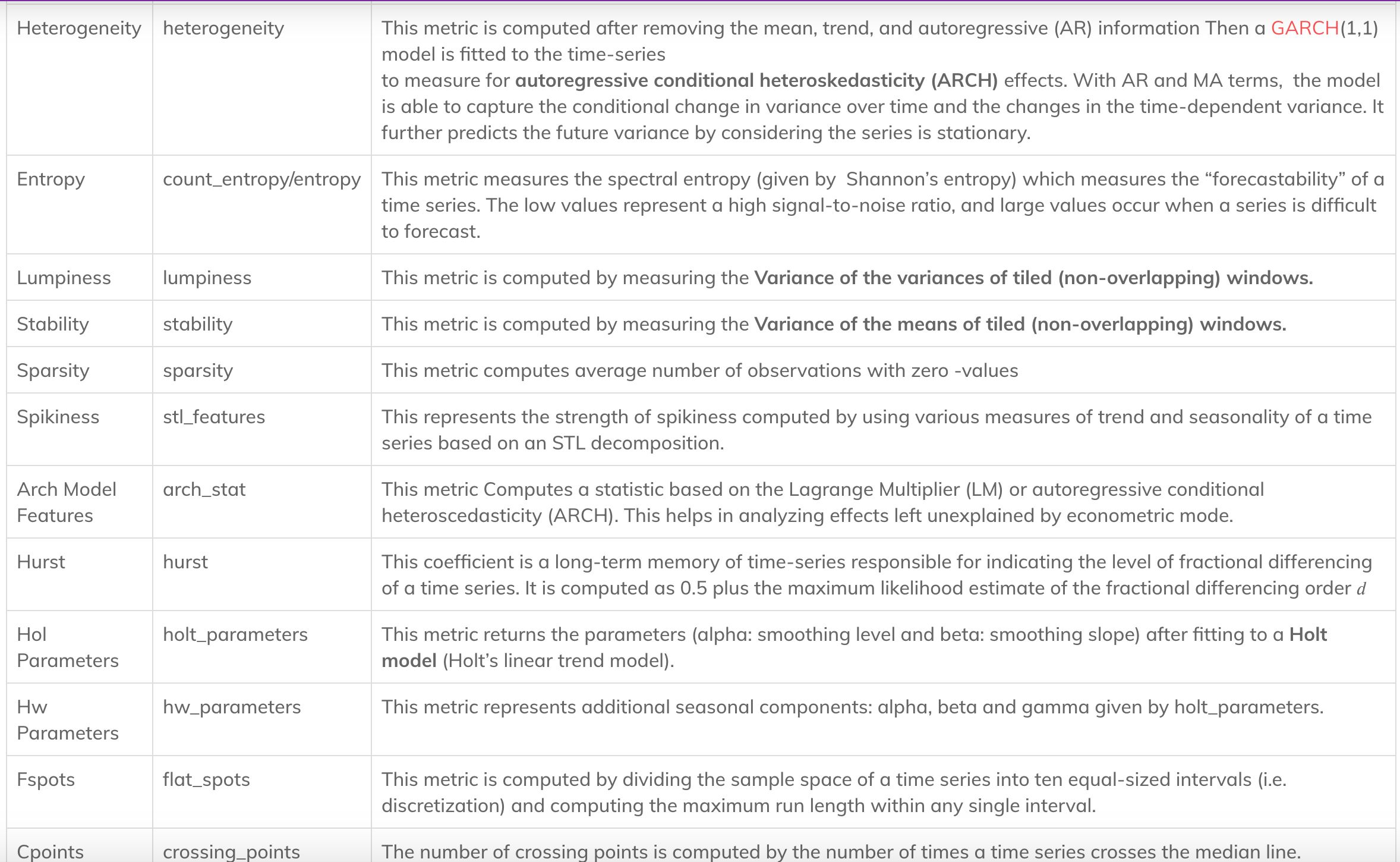
A change in the variance or volatility over time can cause problems when modeling time series with classical methods like ARIMA.
The ARCH or Autoregressive Conditional Heteroskedasticity method plays a vital role in time-series highly volatile models like a stock prediction to measure the change in variance that is time-dependent, such as increasing or decreasing volatility.
Below, we state some of the time-series features, functionality, and their description.

The following code snippet shows how we can extract relevant features with one line of code for each feature.
Source Code
tsf_hp = tf.holt_parameters(df2['# Direct_1'].values)
print(tsf_hp)
tsf_centrpy = tf.count_entropy(df2['# Direct_1'].values)
print(tsf_centrpy)
tsf_crossing_points =tf.crossing_points(df2['# Direct_1'].values)
print(tsf_centrpy)
tsf_entropy =tf.entropy(df2['# Direct_1'].values)
print(tsf_entropy)
tsf_flat_spots =tf.flat_spots(df2['# Direct_1'].values)
print(tsf_flat_spots)
tsf_frequency =tf.frequency(df2['# Direct_1'].values)
print(tsf_frequency)
tsf_heterogeneity = tf.heterogeneity(df2['# Direct_1'].values)
print(tsf_heterogeneity)
tsf_guerrero =tf.guerrero(df2['# Direct_1'].values)
print(tsf_guerrero)
tsf_hurst = tf.hurst(df2['# Direct_1'].values)
print(tsf_hurst)
tsf_hw_parameters = tf.hw_parameters(df2['# Direct_1'].values)
print(tsf_hw_parameters)
tsf_intv = tf.intervals(df2['# Direct_1'].values)
print(tsf_intv)
tsf_lmp = tf.lumpiness(df2['# Direct_1'].values) print(tsf_lmp)
tsf_acf = tf.acf_features(df2['# Direct_1'].values)
print(tsf_acf)
tsf_arch_stat = tf.arch_stat(df2['# Direct_1'].values)
print(tsf_arch_stat)
tsf_pacf = tf.pacf_features(df2['# Direct_1'].values)
print(tsf_pacf)
tsf_sparsity = tf.sparsity(df2['# Direct_1'].values)
print(tsf_sparsity)
tsf_stability = tf.stability(df2['# Direct_1'].values)
print(tsf_stability)
tsf_stl_features = tf.stl_features(df2['# Direct_1'].values)
print(tsf_stl_features)
tsf_unitroot_kpss = tf.unitroot_kpss(df2['# Direct_1'].values)
print(tsf_unitroot_kpss)
tsf_unitroot_pp = tf.unitroot_pp(df2['# Direct_1'].values)
print(tsf_unitroot_pp)The results section illustrates the values of extracted features from Fetal ECG.
Results Time Series -1 (Data from Fetal ECG)
The below figure illustrates a time series of data collected from Fetal ECG from where features have been extracted.

{'alpha': 0.9998016430979507, 'beta': 0.5262228301908355} {'count_entropy': 1.783469256071135} {'crossing_points': 436} {'entropy': 0.6493414196542769} {'flat_spots': 131} {'frequency': 1} {'arch_acf': 0.3347171050143251, 'garch_acf': 0.3347171050143251, 'arch_r2': 0.14089508110660665, 'garch_r2': 0.14089508110660665} {'hurst': 0.4931972012451876} {'hw_alpha': nan, 'hw_beta': nan, 'hw_gamma': nan} {'intervals_mean': 2516.801557547009, 'intervals_sd': nan} {'guerrero': nan} {'lumpiness': 0.01205944072461473} {'x_acf1': 0.8262122472240574, 'x_acf10': 3.079891123506255, 'diff1_acf1': -0.27648384824011435, 'diff1_acf10': 0.08236265771293629, 'diff2_acf1': -0.5980110240921641, 'diff2_acf10': 0.3724461872893135} {'arch_lm': 0.7064704126082555} {'x_pacf5': 0.7303549429779813, 'diff1x_pacf5': 0.09311680507880443, 'diff2x_pacf5': 0.7105000333917864} {'sparsity': 0.0} {'stability': 0.16986190432765097} {'nperiods': 0, 'seasonal_period': 1, 'trend': nan, 'spike': nan, 'linearity': nan, 'curvature': nan, 'e_acf1': nan, 'e_acf10': nan} {'unitroot_kpss': 0.06485903737928193} {'unitroot_pp': -908.3309773009415}
The results section illustrates the values of extracted features for date wise temperature variation.
Result Time-Series 2 (Data from Daily Temperature)

{kind=link}
{'alpha': 0.4387345064923509, 'beta': 0.0} {'count_entropy': -101348.71338310161} {'crossing_points': 706} {'entropy': 0.5089893350876903} {'flat_spots': 10} {'frequency': 1} {'arch_acf': 0.016273743642920828, 'garch_acf': 0.016273743642920828, 'arch_r2': 0.015091960217949008, 'garch_r2': 0.015091960217949008} {'hurst': 0.5716257806690483} {'hw_alpha': nan, 'hw_beta': nan, 'hw_gamma': nan} {'intervals_mean': 1216.0, 'intervals_sd': 1299.2740280633643} {'guerrero': nan} {'lumpiness': 5.464398615083545e-05} {'x_acf1': -0.0005483958183129098, 'x_acf10': 3.0147995912148108e-06, 'diff1_acf1': -0.5, 'diff1_acf10': 0.25, 'diff2_acf1': -0.6666666666666666, 'diff2_acf10': 0.4722222222222222} {'arch_lm': 3.6528279285796827e-06} {'nonlinearity': 0.0} {'x_pacf5': 1.5086491342316237e-06, 'diff1x_pacf5': 0.49138888888888893, 'diff2x_pacf5': 1.04718820861678} {'sparsity': 0.0} {'stability': 5.464398615083545e-05} {'nperiods': 0, 'seasonal_period': 1, 'trend': nan, 'spike': nan, 'linearity': nan, 'curvature': nan, 'e_acf1': nan, 'e_acf10': nan} {'unitroot_kpss': 0.29884876591708787} {'unitroot_pp': -3643.7791982866393} Conclusion
- In this blog, we discuss easy steps to extract features from time series (both time-series have seasonality =1), which can help us in discovering anomalies.
- It is evident from the computed metrics that the first series is more stable (higher value as given by the stability and entropy factor) as the time-stamped data is for a longer period with relatively few fluctuations compared to its entire period.
- The second time series exhibits higher fluctuations as demonstrated by a high number of crossing points.
- Consequently, we also observe that the second time-series also has a lower lumpiness and intervals mean, signifying a lower variance of variance.
- unirooot_kpss and uniroot_pp reveal the existence of a unit root in the vector which in both the time-series is less than 1 and negative respectively.
- tsfeature also supports evaluation of custom functions that come as a NumPy array as input and returns a dictionary with the feature name as a key and its value
References
- https://github.com/FedericoGarza/tsfeatures
- https://htmlpreview.github.io/?
- https://github.com/robjhyndman/M4metalearning/blob/master/docs/M4_methodology.html#featureshttps://cran.r-
- project.org/web/packages/tsfeatures/tsfeatures.pdf
- https://robjhyndman.com/papers/icdm2015.pdf
- https://math.berkeley.edu/~btw/thesis4.pdf
- https://machinelearningmastery.com/develop-arch-and-garch-models-for-time-series-forecasting-in-python/
- https://ir.nctu.edu.tw/bitstream/11536/14555/1/A1997YD78100005.pdf
- Principal Component Analysis for Time Series and Other Non-Independent Data – https://link.springer.com/chapter/10.1007%2F0-387-22440-8_12
http://www.datasciencecentral.com/xn/detail/6448529:BlogPost:1003249
{kind=link}